LLM coding question comparison using Ollama
29 July 2024Now Ollama has made it simple enough for anyone who can use a terminal to run large language models locally, naturally I’ve gone overboard downloading too many to play with. I’m increasingly feeling they definitely have a place in the devops/coding arsenal of tools, but which model is best?
If you go on HuggingFace to look at a new model you’re interested, they often have great comparisons like this.
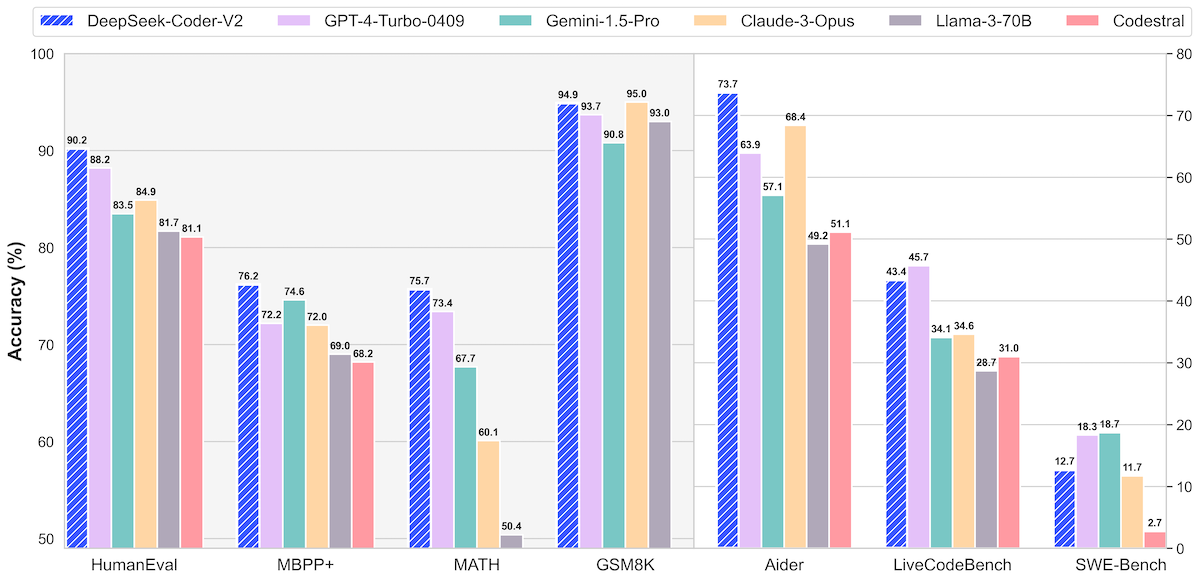
There has been a lot of work in crafting these and other benchmarks which are often comprehensive and well thought out. I’ve also seen people doing fun things, like this guy , who is just pasting coding challenges off a web page into an LLM and seeing if it can solve them (spoiler - mostly it can solve coding problems that are probably part of it’s training set ).
A factor to keep in mind when looking at these charts is that they are probably running unquantised (uncompressed is a close enough analogy) models on fleets of $60K graphics cards . I can use that if I pay them $20 a month and have an internet connection, but I want to pay $0 and run it on my M1 MacBook - that’s why I downloaded Ollama .
So what follows is my completely unscientific testing of the models I’ve downloaded. Basically, I’ll ask them the same question (that I think I know the answer to) and time their response, and subjectively judge their output. For the question I’ve chosen:
Thinking about Docker, what’s the difference between [CMD] and [EntryPoint]?
This seems like a fairly specific bit of knowledge someone might want to know about, I know the answer, and the first page of google results are mostly good so there should be sufficient training data. I’ve put both terms in square brackets as a red herring, and same with the camelcase for ENTRYPOINT. I also didn’t specify that these are both usually defined in the dockerfile. I’ve had a go at the same question, and published it here last week .
The results
According to me, I am the winner.

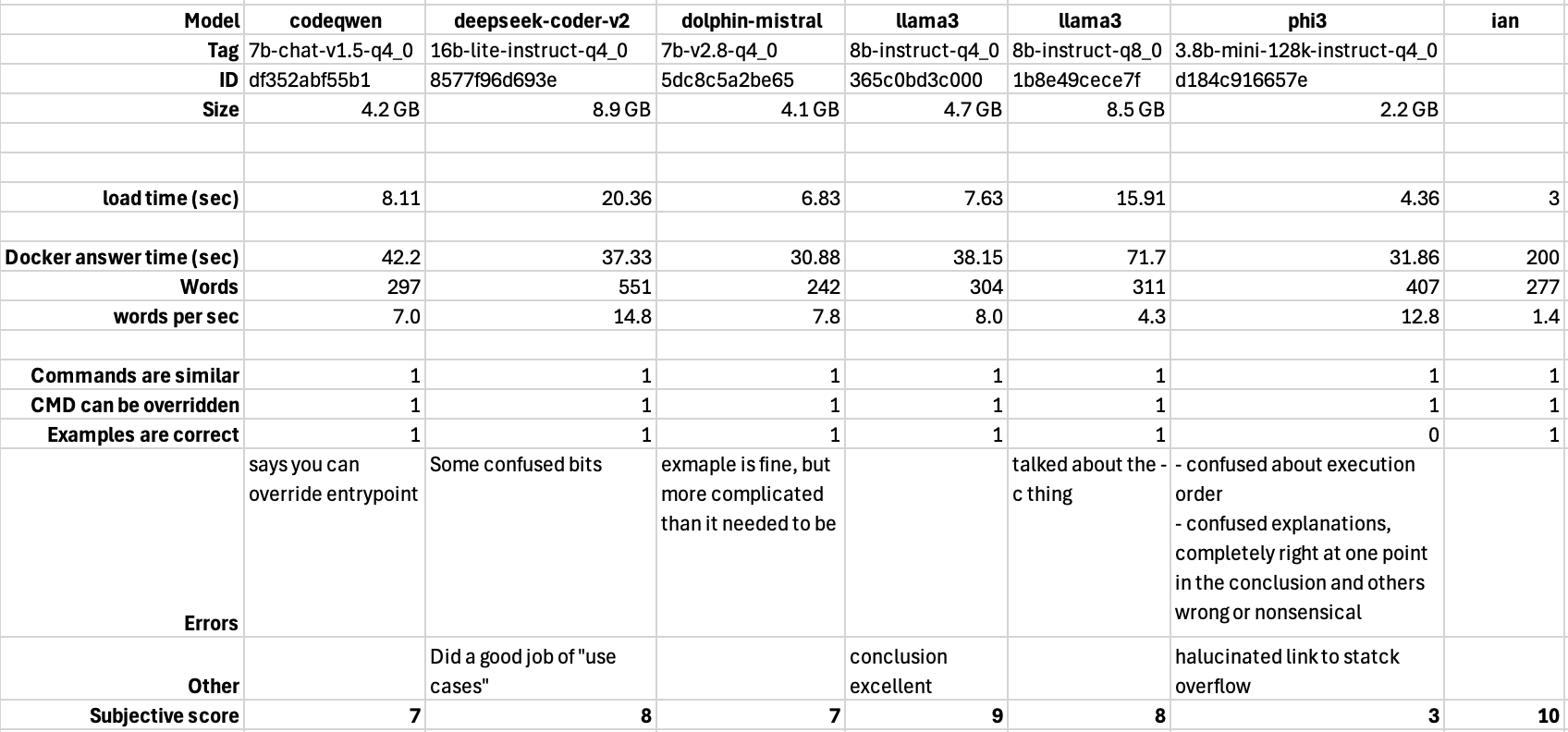
The word count for my answer would be a bit higher if we counted the text in my images, which we probably should. I made up my times by guessing what they’d be if you asked me this question.
The contestants
codeqwen and deepseek-coder are both optimised for chatting about code, which I’m claiming Docker skills are a legitimate part of. They both also do autocomplete, and I’m using codeqwen for that in VSCode. deepseek-coder is about twice as big, and you’d think better, which it was, but in my opinion, only a little. codeqwen had a clear error and deepseek-coder was a bit muddled in some parts but did a great job of wrapping it up with an explanation of where you’d use both.
phi3’s is small (half the size of most of the others here) and great for chatting. For general questions it’s very impressive for it’s size, but was useless for this task. It’s interesting to me that the smartest and the stupidest AI’s had the most to say, and that my explanation was almost the exact size of all the others.
dolphin-mistral’s claim to fame is that it’s uncensored. So if you ask it how to build an improvised explosive, overturn an election, or trick a co-worker into falling in love with you, it will happily tell you - something the other models here cannot. Basically, it laughs at the first law of robotics. Even though launching a Docker container is not illegal or unethical, it had a reasonable, usable answer for our question.
I tried two versions of llama3. To explain the difference, we need to go into an explanation of how large language models work, which I don’t know, so I’m just going to hallucinate it for you:

If you vacuum up heaps of input (the training data), then filter out all the cruft (’the’, ‘a’, ’not)’, then put it into a special multidimensional database so that similar things are near each other (eg ‘rose’ is near ‘flower’, ‘red’ and ’titanic’ and a long way from ‘bulldozer’ and ‘antidisestablishmentarianism’) and the database also includes how far away from each other those things are, then it is very, very, big. Too big to put on my MacBook.
We can reduce the size of it by ‘quantising’ it which is a word I’ve heard on a podcast and might mean reducing the resolution of the numbers representing the distances between concepts in the database. This is the ‘q8’ and ‘q4’ you can see in the tags in the table. ‘q4’ is going to be smaller, but less accurate than a ‘q8’ of the same data.
That’s the situation with these two versions of llama3 - one is more ‘compressed’. The relationship between the quantitation and the usefulness of the model is not linear for many applications, and that seems to be the case here. The bigger model did produce some more detail, but I actually preferred the output of the smaller one.
Conclusion
It would be foolish to put much weight on a conclusion from a single run of a dubious test analyzed by a subjective carbon based lifeform, but anyway…
- All of these models produced a useful starting point except phi3. You probably could have just used what the others produced and gone on working with your dockerfile and things would have worked out fine.
- llama3’s performance matches my experience of other times I’ve been using it. It’s just pretty great for what it is.
- Most of the explanations over-complicated things - this probably could have been fixed with a better prompt.
- It’s sort of magic when you think this is most of the world’s knowledge squashed into 4GB on my laptop in a form I can just ask questions of
- There is room for improvement
It’s easy to imagine that if these models were able to reach out to the internet and check what they’d come up with then generate a response by combining their first guess and their new knowledge, they’d be a lot better. That’s basically what Perplexity does, and it’s output is better than any of my local models, and it includes some of the links it used which would probably clear up any further questions. That sort of functionality is not far away for local models, and something like it is running in AnythingLLM , so I expect these will be indispensable tools in a year.